AI agents have become remarkably capable at generating code and executing CLI commands, largely due to the abundance of training data and benchmarks that focus on improving these capabilities. Coding agents initially started off as assistants, but are now showing signs of being able to take on larger tasks autonomously with little or no human supervision.
However, these capabilities are still nascent. Benchmarks for long-horizon, production-grade engineering remain largely unexplored, and training environments for improving these capabilities are scarce.
We're introducing Systems-Bench, a benchmark that evaluates the ability of AI agents to perform long-horizon tasks in production-grade environments involving a variety of services and tools.
We created a sandboxed environment that has all of the components of a software engineering company: Slack, Linear, Notion, Sentry, Prometheus, deployment tools, and a full-stack app with live traffic. We then asked AI agents to complete large, multi-step tasks: implement features, deploy, monitor, and respond to incidents. Finally, we measured the performance of agents in terms of feature correctness, deployment & devops, and engineering quality.
Principles
Systems-Bench adopts the following principles:
Production-grade systems. Agents implement, deploy, and monitor production-grade systems consisting of multiple components (e.g. frontend, backend, databases, object stores, caches).
Tool use. Success depends on coordination across multiple tools (e.g. Linear, Sentry, Slack, Notion, GitHub, CI/CD). Agents interact with tools through MCP.
Long-horizon reasoning. Solving requires planning, sequencing, and judgment, not just local code correctness. Solutions can appear correct but fail under integration or rollout conditions.
Stateful, evolving environments. The environment is stateful and evolving (data, traffic, background jobs, metrics change over time, but are seeded to ensure reproducibility).
Verifiable outcomes and partial credit. Agents are assessed based on verifiable outcomes, instead of prescriptive solutions. Partial credit is assigned due to the difficulty of tasks.
Real interactions. Traffic and requests flow through real containerized services and tools in order to ensure realism in the environment.
Environments
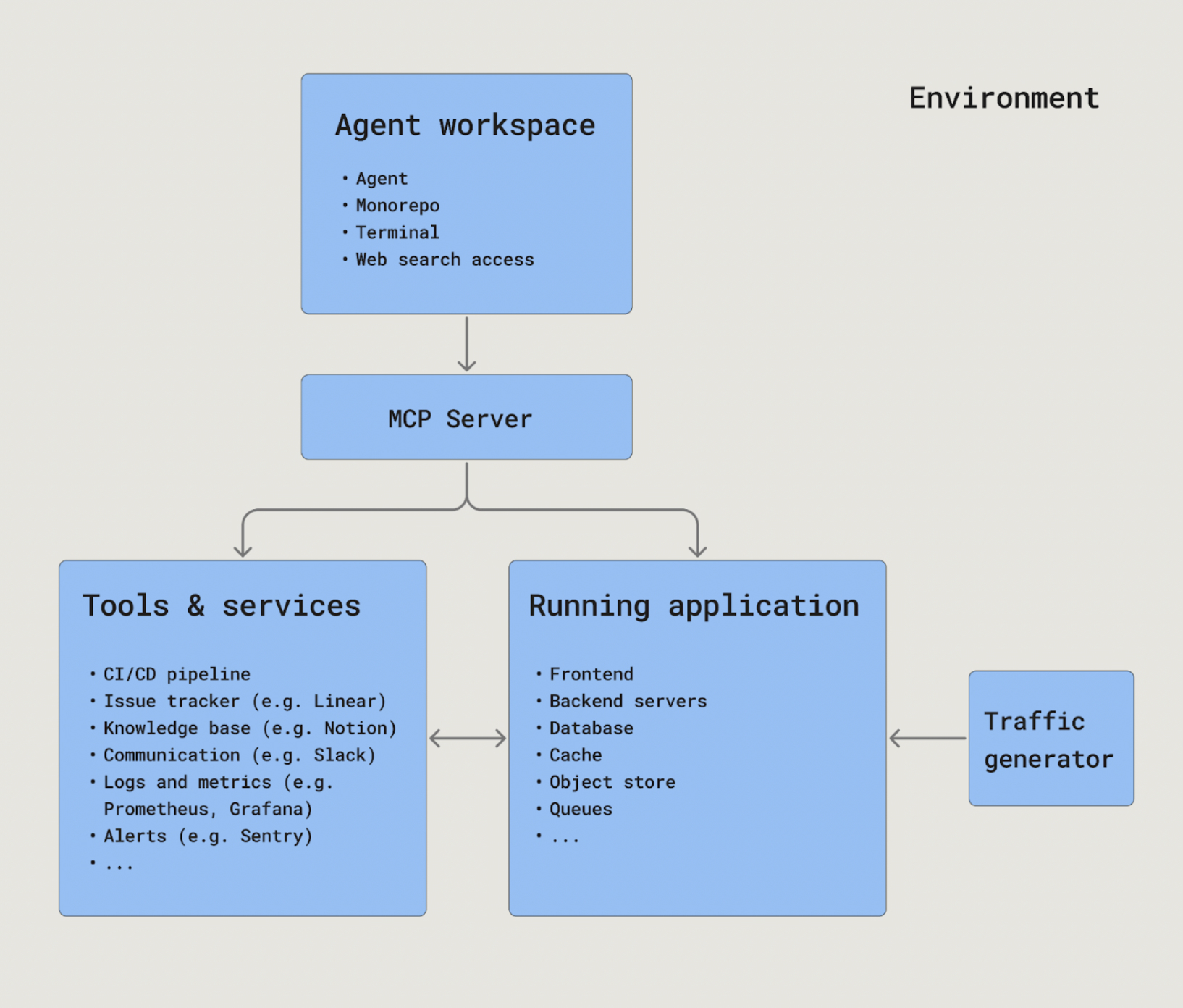
Systems-Bench evaluates coding agents within an environment that reflects the tools, services, and procedures that software engineers interact with. An environment consists of:
An agent workspace which contains the monorepo that the agent can read and edit. Within the workspace, the agent can also execute bash commands and call tools.
An MCP server which allows agents to interact with the tools that software engineers use.
Tools and services, which includes applications for tracking issues (e.g. Linear), a knowledge base (e.g. Notion), communication tools (e.g. Slack), logs and metrics (e.g. Prometheus & Grafana), deployment tools, alarms, metrics, and alerting tools (e.g. Sentry).
A running application, which is deployed from the service code that the monorepo contains. The monorepo used in Systems-Bench contains 20,000+ human-authored commits. The code is deployed into a running application that contains a frontend, backend servers, databases, object stores, caches, and queues. The application is running when the agent starts on the task, and the agent can re-deploy after making code changes.
A traffic generator which drives synthetic traffic to the running application.
When the environment is initialized, it is seeded with initial data that populates issue trackers, communication tools, and the company knowledge base.
Tasks
Tasks in Systems-Bench are designed to involve changes across a large surface area of components in order to evaluate tool use abilities and long-horizon planning. We evaluate agent performance on 50 diverse tasks that measure the ability of agents to implement, deploy, monitor, and debug complex production systems.
Below is a high level description of some of the tasks in Systems-Bench:
Multi-service feature rollout. Implement a feature spanning multiple services or system components, requiring coordinated changes and correct deployment sequencing. The task is complete when the feature works end-to-end and no alarms fire due to incorrect deployment ordering or cross-service incompatibilities.
Feature flag implementation. Add a new feature to an existing service and gate it behind a runtime feature flag, without introducing breaking API changes. The task is complete when the flag correctly controls behavior for targeted versus non-targeted users without regression.
Security incident response. Investigate suspicious activity, fix the underlying vulnerability, update Sentry ticket and public system status. The task is complete when the vulnerability is patched, exploit attempts are blocked, and an audit report is produced.
Latency optimization. Diagnose and resolve a latency issue causing SLO violations. The task is complete when latency metrics return to acceptable thresholds without regression in correctness or error rates.
Error rate reduction. Reduce error rates by implementing reliability improvements (timeouts, retries, fallbacks, etc.). The task is complete when error rates decrease to acceptable thresholds and the system handles failure scenarios gracefully.
API migration. Deprecate a legacy API while migrating existing traffic to a new version. The task is complete when all traffic uses the new API and the legacy endpoint is decommissioned without errors.
Flaky test remediation. Fix intermittently failing tests in the monorepo to achieve consistent, reliable test behavior. If the issue is due to service code, fix the service code. The task is complete when previously flaky tests pass consistently across multiple runs without being skipped or disabled.
Example
To concretely illustrate Systems-Bench's evaluation methodology, we trace a single task: replacing a global "allow anonymous browsing" boolean with four granular access controls in a production codebase. The change touches the database schema, admin UI dashboard, API authorization logic, and client-side navigation. Below is a condensed agent trajectory.
- The agent tracks usage across the codebase and MCP tools, finding references in backend controllers, config layers, admin UI, serializers, and locale files.
- The agent executes coordinated changes across the entire stack: config defaults, backend controllers, admin models and views, in addition to unit, integration, and UI testing.
- The agent queries metrics and logs to establish baseline health.
- The agent deploys, and queries metrics and logs again. However, it encounters failures caused by a missing database migration.
This case reflects a pattern we observe across Systems-Bench: agents handle application-layer reasoning well but fail to account for the full engineering lifecycle. Migrations, build pipelines, and deployment sequencing require planning beyond code generation, and these failure modes only surface when evaluating agents in production-grade environments.
Grading
Systems-Bench evaluates models on 3 dimensions which capture the elements of engineering competency:
Feature correctness. Evaluates whether the newly introduced feature satisfies the task specification. Correctness is determined by build success or failure, unit tests, and integration tests. Regressions on existing features are penalized.
Deployment & DevOps. Assesses how reliably the agent can test and deploy changes to production. The environment contains alarms and canaries, and the Systems-Bench harness penalizes deployments that set off alerts.
Engineering Quality. Evaluates whether the agent maintains high code quality and engineering best practices. An LLM judge assesses commit scope, code maintainability, and documentation. Penalties apply for security issues, non-performant code, and unproductive loops in the agent's trajectory.
Due to the complexity of the tasks in Systems-Bench, we introduce two scoring frameworks: pass / fail and partial credit.
Pass / Fail
Systems-Bench-PF uses strict binary grading: a task is marked as passed only if the agent achieves a full score on the feature correctness and deployment verifiers. Engineering quality is excluded from this framework due to its subjective nature.
All models are evaluated using the OpenHands agent harness in order to compare model performance. Under pass/fail scoring, even the strongest models complete only about one in five runs successfully end-to-end. Claude Opus 4.5 and Claude Sonnet 4.5 lead at a roughly 21–22% success rate, followed closely by Gemini 3 Pro and GPT-5.2 Codex.
Partial Credit
Systems-Bench-PC uses a grading framework that produces a composite score consisting of feature correctness (60%), deployment & devops (30%), and engineering quality (10%). In each category, partial credit is assigned due to the complexity and duration of the tasks.
With partial credit scoring, Claude Opus 4.5 leads this benchmark, followed by GPT-5.2 Codex and Claude Sonnet 4.5.
Notably, most models perform better on Feature Correctness than on Deployment & DevOps. This reflects how current models are optimized for code generation, and are not yet reliable at deploying features end-to-end and operating production systems. Closing this gap will be important for advancing long-running agents in the software engineering domain.